
Introduction to Datacenter Technology
This article provides a technical overview of datacenter technologies and systems. Datacenters form the backbone of the digital world, acting as the central hubs where computing resources are concentrated for remote access. These sprawling complexes of servers, networking equipment, and other hardware allow for the seamless delivery and storage of data, applications, and services.
A few brilliant resources to get yourself familiar with modern data center technologies and technical terminology are the following, referring to Microsoft Azure:
- https://azure.microsoft.com/en-us/explore/global-infrastructure
- https://datacenters.microsoft.com/
- https://learn.microsoft.com/en-us/compliance/assurance/assurance-datacenter-architecture-infrastructure
- https://stefanos.cloud/inside-azure-datacenter-architecture-with-mark-russinovich/
How does working inside a modern data center look like? Have a look at the following videos on Azure and AWS.
Hardware Infrastructure
Servers are the core computing units. You will find various types of servers such as application servers, database servers, and web servers, among others. Networking Equipment ranges from switches to routers to load balancers. The networking equipment in a data center ensures that data packets reach their intended destinations. Storage systems, usually accessible via storage area networks (SAN), allow for the secure and high-speed access to stored data.
Software Infrastructure
Operating Systems,primarily Linux and Windows Server are among the popular choices for server operating systems in data centers. Virtualization technologies like VMware, Hyper-V, and KVM allow for the efficient use of hardware resources by allowing multiple virtual instances to run on a single physical host. Management and Automation Software tools like Ansible, Puppet, and Azure Resource Manager are used for automating the configuration, deployment, and management of hardware and software resources.
The Cloud Era
Modern datacenters are increasingly integrated with cloud computing platforms such as Microsoft Azure, AWS, and Google Cloud. These platforms provide a layer of abstraction over physical hardware, allowing businesses to scale resources elastically based on demand.
Emerging Technologies
Artificial Intelligence (AI) algorithms often require significant computing power, and datacenters are evolving to include dedicated AI servers equipped with GPUs and TPUs for machine learning tasks. Edge Computing datacenters are also becoming more decentralized to bring computing closer to the data source, a trend known as edge computing. Hyperscale computing involves deploying thousands or even millions of servers that can work in parallel to handle compute-intensive tasks. Examples of hyperscale computing are container orchestration systems, such as Kubernetes, AI and ML workloads and serverless computing. Hyperscale networking involves the use of software-defined networking (SDN) and network function virtualization (NFV) to dynamically allocate network resources and optimize data flow. Hyperscale storage involves the use of distributed file systems (e.g. Hadoop HDFS or Ceph) and object storage (e.g. Amazon S3) solutions that can scale horizontally to accommodate growing data volumes.
Hyperscale
In the context of modern datacenters, the term "hyperscale" refers to the capability to scale compute, networking, and storage resources exponentially to meet the demands of high-growth workloads and applications. Hyperscale datacenters are designed to provide on-demand scalability and are optimized for automation, high availability, and operational efficiency. These datacenters are often deployed by large cloud providers, social media companies, and any enterprise that requires massive computational power and storage capacity.
Datacenter Safety, Security, and Construction
Types of Datacenters Based on Certification
Tier 1 Datacenters
Tier 1 facilities are basic datacenters with a single, non-redundant distribution path for power and cooling. They generally offer 99.671% availability.
Tier 2 Datacenters
These datacenters offer redundant components but only a single path for power and cooling. The expected availability is around 99.741%.
Tier 3 Datacenters
Tier 3 facilities provide dual power and cooling paths but use only one at a time. They are designed to provide 99.982% availability.
Tier 4 Datacenters
The crème de la crème of datacenters, Tier 4 offers fully fault-tolerant infrastructure with 2N+1 fully redundant systems, guaranteeing 99.995% availability.
Protection Against Natural Disasters
Data centers should have a design to withstand the following natural and man-made disasters.
- Earthquake-Resistant Design. Datacenters in seismic zones are often constructed based on seismic design criteria like the California Building Code or Japan's Building Standard Law.
- Flood Barriers.
- In flood-prone areas, barriers and pumping systems are often installed.
- Fire Suppression Systems.
- FM-200 and NOVEC 1230 are commonly used clean agent fire suppressants, designed to extinguish a fire quickly without harming the equipment.
- Riot Control.
- Datacenters are generally constructed with reinforced concrete walls and bullet-proof glass to protect against external attacks.
- Nuclear-Proof Construction.
- Though less common, some high-security datacenters are designed to withstand nuclear blasts and radiation.
Global Maps and Directories
Global directories and maps that list datacenters worldwide are available through platforms like Data Center Map and CloudScene. These resources offer insights into the locations, risk profiles, and certifications of datacenters.
Supporting Installations and Systems
The types of supported power generators range among the following types.
- Diesel Generators.
- These are commonly used for backup power, generally featuring an automatic transfer switch (ATS) to ensure immediate power supply during an outage.
- Natural Gas Generators.
- An alternative to diesel, natural gas generators produce fewer emissions but are generally more expensive.
- Renewable Energy Generators.
- Solar and wind power generators are gaining prominence for sustainable power supply, although they are typically not reliable enough to be sole backup options.
Cooling Systems
The types of supported cooling systems range among the following types.
- Air Cooling. The most basic form of cooling, air-cooled systems rely on air conditioners and ventilators to manage temperature.
- Water Cooling.
- A more efficient but complex system, water cooling uses water as a heat exchange medium to remove heat from servers.
- Immersive Liquid Cooling.
- This cutting-edge technology submerges server components in a non-conductive liquid to effectively manage heat.
Physical Security Systems
The types of supported physical security systems range among the following types.
- Perimeter Fencing. A physical barrier like a fence or wall usually surrounds the datacenter property for initial security.
- Surveillance Cameras.
- High-definition cameras monitor every angle of the facility, often featuring infrared for nighttime visibility.
- Biometric Access.
- Fingerprint, iris, or face recognition systems are used for multi-factor authentication, ensuring only authorized personnel gain access.
The following video provides an overview of Google Cloud Platform data centers 6-layer security design.
Operations Room
The operations room in a modern datacenter serves as the nerve center for monitoring, managing, and maintaining the datacenter's infrastructure. It is equipped with advanced technologies and tools that enable real-time oversight of various aspects such as compute, networking, storage, security, and environmental controls. This description aims to provide a comprehensive overview of what is typically included in the operations room of a state-of-the-art datacenter. Typical components of an operations room are the following.
- Monitoring Dashboards
- Role: Real-time Monitoring
- Description: Large screens displaying real-time metrics and KPIs related to server health, network performance, and storage utilization. Monitoring systems utilize alerting mechanisms for administrators to be alerted of abnormal situations by email, sms or instant messaging.
- Incident Management Systems
- Role: Incident Tracking and Resolution
- Description: Software platforms that help in logging, tracking, and managing incidents. They often integrate with alerting systems for immediate notification of issues.
- Network Operations Console
- Role: Network Monitoring and Management
- Description: Specialized consoles that provide a detailed view of network traffic, performance, and security posture.
- Server Management Stations
- Role: Server Monitoring and Control
- Description: Workstations equipped with software tools for remote server management, including provisioning, patching, and decommissioning.
- Security Operations Center (SOC)
- Role: Security Monitoring
- Description: A dedicated section within the operations room focused on monitoring security alerts, analyzing security data, and initiating responses to security incidents.
- Environmental Control Panel
- Role: Environmental Monitoring
- Description: Panels that display real-time data on temperature, humidity, and airflow within the datacenter. Often integrated with HVAC systems for automated control.
- Communication Systems
- Role: Internal and External Communication
- Description: Systems like IP phones, intercoms, and video conferencing tools to facilitate communication among team members and with external stakeholders.
- Backup Power Controls
- Role: Power Management
- Description: Interfaces for managing backup power solutions like UPS (Uninterruptible Power Supply) and generators.
- Documentation and Manuals
- Role: Reference Material
- Description: Physical or digital documentation that provides guidelines, procedures, and protocols for various operations.
- Emergency Response Kits
- Role: Crisis Management
- Description: Kits containing essential tools and materials for handling emergencies, such as network failures or security breaches.
The operations room utilizes a series of automation and orchestration tools and technologies for automatically and intelligently managing the data center resources, services and workloads.
Core Server Rooms
Rack Architecture
Rack Types
Racks serve as the foundational infrastructure in a datacenter, housing various types of equipment such as servers, switches, and storage devices. The choice of rack type can significantly impact the datacenter's operational efficiency, scalability, and airflow management. Standard server racks usually come in 42U, 45U, or 48U sizes, with a 'U' denoting 1.75 inches of rack space. The following types of racks are available.
- Open Frame Racks
- Description: These are essentially frame structures without sides or doors.
- Use Case: Ideal for applications that don't require physical security and where ease of access is a priority.
- Enclosed Racks
- Description: These come with removable side panels and doors, often lockable.
- Use Case: Suitable for environments that require added security and controlled airflow.
- Wall-Mount Racks
- Description: These are smaller racks designed to be mounted on a wall.
- Use Case: Ideal for smaller installations or remote locations where floor space is limited.
- Two-Post Racks
- Description: These racks have two vertical posts and are generally used for lightweight equipment.
- Use Case: Suitable for network equipment like switches and patch panels.
- Four-Post Racks
- Description: These racks have four vertical posts and are more robust, designed for heavier equipment.
- Use Case: Ideal for servers, UPS systems, and other heavy devices.
Rails and Supports
Rails, either square-hole or round-hole, support servers and other hardware. The choice often depends on the specific vendor's mounting options. Rails are the components within a rack that provide the mounting points for various types of equipment. The choice of rail type is crucial for ensuring that the equipment is securely and efficiently mounted. The following types of rails are available.
- Static Rails
- Description: Fixed-length rails that do not extend out of the rack.
- Supported Equipment: Generally used for lighter equipment like switches and patch panels.
- Sliding Rails
- Description: Extendable rails that allow the equipment to be pulled out of the rack for maintenance.
- Supported Equipment: Commonly used for servers and storage arrays that require frequent maintenance.
- Universal Rails
- Description: Adjustable rails that can fit various types of equipment.
- Supported Equipment: Suitable for a mix of servers, switches, and other devices that have different mounting requirements.
- Tool-less Rails
- Description: Rails that can be installed without the need for tools.
- Supported Equipment: Ideal for rapid deployments and for equipment that doesn't require specialized mounting.
Patch Panels
Patch panels serve as the interface between the networking equipment and the network itself. They are crucial for cable management and can significantly impact the efficiency and reliability of the network. Optical and copper patch panels serve as interfaces for network cables both for data and voice (VoIP) traffic. Optical panels are used for long-distance and high-speed connections, whereas copper is generally for shorter distances. The following types of patch panels are available.
- Ethernet Patch Panels
- Description: Used for connecting Ethernet cables.
- Interconnectivity: Generally used for LAN connections and can be interconnected using Cat5e, Cat6, or Cat6a cables.
- Fiber Optic Patch Panels
- Description: Used for connecting fiber optic cables.
- Interconnectivity: Ideal for high-speed data transmissions and can be interconnected using single-mode or multi-mode fiber cables.
- Coaxial Patch Panels
- Description: Used for connecting coaxial cables.
- Interconnectivity: Generally used for video and broadband signals.
- Blank Patch Panels
- Description: These are empty panels that can be customized with various types of ports.
- Interconnectivity: Suitable for specialized or mixed environments that require different types of connections.
Power Infrastructure
Power Banks and PDUs
Power Distribution Units (PDUs) serve as the electrical backbone. Modern PDUs feature remote monitoring and load balancing. Power distribution is a critical aspect of datacenter operations, ensuring that all equipment receives the necessary electrical supply for uninterrupted functioning. Power Distribution Units (PDUs) and power banks are essential components in this regard. The following types of PDUs are available.
- Basic PDUs
- Description: These are essentially power strips that distribute power to multiple devices.
- Use Case: Suitable for less complex setups where advanced features like remote monitoring are not required.
- Metered PDUs
- Description: These PDUs come with a built-in meter to monitor power consumption.
- Use Case: Ideal for environments where tracking power usage is important but remote control is not necessary.
- Switched PDUs
- Description: These allow for remote control of individual outlets.
- Use Case: Useful in scenarios where remote rebooting or power cycling is required.
- Intelligent PDUs
- Description: These offer advanced features like remote monitoring and control, as well as environmental monitoring.
- Use Case: Ideal for complex, large-scale datacenters where both power and environmental factors need to be closely monitored.
- Power Banks
- Description: These are large-scale battery units designed to provide backup power.
- Use Case: Used as a secondary power source to ensure uninterrupted power supply.
Electrical Fuses
Electrical fuses act as safety devices that interrupt excessive current flow, protecting the equipment and circuits. Commercial connector protocols standardize the types of connectors used, ensuring compatibility and safety. The following types of fuses are available. The most common industrial electrical fuse/cable specifications are IEC 60309, NEMA and BS 1363.
- Cartridge Fuses
- Description: Enclosed in a cylindrical cartridge.
- Connector Protocol: Ferrule and knife-blade types.
- Blade Fuses
- Description: Designed with a plastic body and two metal prongs.
- Connector Protocol: Standard blade connectors.
- Glass Fuses
- Description: Glass tube with metal end caps.
- Connector Protocol: Snap-in or bolt-down types.
- High Rupture Capacity (HRC) Fuses
- Description: Designed to handle significant overload conditions.
- Connector Protocol: Bolted or clip-in types.
ATS/STS Systems
Automatic Transfer Switches (ATS), Static Transfer Switches (STS), and Uninterruptible Power Supplies (UPS) are critical for ensuring power redundancy and reliability in a datacenter. Automatic Transfer Switch (ATS) and Static Transfer Switch (STS) systems provide power redundancy to devices that lack multiple Power Supply Units (PSUs). A comparison among STS, ATS and UPS can be found at https://stefanos.cloud/difference-between-ats-sts-standby-online-and-line-interactive-ups/. The types of ATS, STS and UPS systems are the following.
- Automatic Transfer Switches (ATS)
- Description: Automatically switches power sources when the primary source fails.
- Use Case: Ideal for datacenters with dual power feeds.
- Static Transfer Switches (STS)
- Description: Uses power semiconductors for faster switching between power sources.
- Use Case: Suitable for critical loads requiring quick transfer times.
- Standby UPS Systems
- Description: Provides power backup only when the primary source fails.
- Use Case: Suitable for less critical loads.
- Line-Interactive UPS Systems
- Description: Provides voltage regulation along with power backup.
- Use Case: Ideal for environments with fluctuating voltage levels.
- Double-Conversion UPS Systems
- Description: Continuously converts incoming AC power to DC power, then back to AC.
- Use Case: Suitable for mission-critical applications requiring high-quality power.
Hardware Categories
Compute Hardware
In today's datacenter ecosystem, compute power is a critical resource that drives a wide array of applications, from basic web services to complex machine learning algorithms. The choice of server type and compute power significantly impacts the performance, scalability, and efficiency of datacenter operations. This overview aims to provide a comprehensive understanding of the various types of compute power and server configurations available in modern datacenters, including Rack Servers, Blade Servers, and specialized AI Servers with TPUs and GPUs.
- Rack Servers
- Role: General-Purpose Computing
- Characteristics:
- Standalone servers that fit into a standard 19-inch rack.
- Scalable and easy to manage.
- Suitable for small to medium-sized datacenters.
- Compute Power:
- Varies from single-socket to multi-socket configurations.
- Supports a wide range of CPUs, from basic to high-performance.
- Blade Servers
- Role: High-Density Computing
- Characteristics:
- Designed to fit into a blade chassis.
- High density, allowing for more compute power in less space.
- Ideal for large-scale virtualization.
- Compute Power:
- Typically multi-socket configurations.
- Optimized for high-throughput workloads.
- AI Servers with TPUs (Tensor Processing Units)
- Role: Specialized for Machine Learning and AI
- Characteristics:
- Custom-designed to accelerate tensor computations.
- Highly efficient for deep learning tasks.
- Compute Power:
- Specialized TPUs that offer high TOPS (Tera Operations Per Second).
- Optimized for low-precision arithmetic to accelerate machine learning inference and training.
- AI Servers with GPUs (Graphics Processing Units)
- Role: General-Purpose and AI Computing
- Characteristics:
- Versatile, capable of handling both general-purpose and specialized computations.
- Widely used for machine learning, data analytics, and graphical tasks.
- Compute Power:
- High-performance GPUs capable of a large number of floating-point operations per second (FLOPS).
- CUDA and OpenCL support for software-level optimization.
- Hyper-Converged Servers
- Role: Integrated Computing, Storage, and Networking
- Characteristics:
- Combines compute, storage, and networking into a single system.
- Simplifies management and scalability.
- Compute Power:
- Varies based on configuration but generally optimized for virtualized environments.
- Mainframe Servers
- Role: Enterprise-Level Computing
- Characteristics:
- High availability and reliability.
- Suitable for mission-critical applications.
- Compute Power:
- Extremely high, optimized for transaction processing and data analytics.
Networking hardware
In contemporary datacenter architectures, networking appliances serve as the backbone for ensuring efficient data flow, security, and high availability. These appliances range from basic networking hardware like switches to specialized devices designed for security and load distribution. This overview aims to elucidate the roles and functionalities of key networking appliances such as Firewalls, IDS/IPS, VPN concentrators, Load Balancers, Proxies, and Core/Distribution/Access Switches.
OSI Layer Components: The OSI (Open Systems Interconnection) model is a conceptual framework that standardizes the functions of a telecommunication or computing system into seven distinct layers. Let's briefly examine each layer:
- Physical Layer (Layer 1):
- Components: Fiber, copper, coaxial, cable
- Interfaces: RJ45 connectors for Ethernet, LC connectors for fiber optics
- Example: Cat 6 Ethernet cables
- Data Link Layer (Layer 2):
- Components: Ethernet, Industrial Ethernet protocols
- Non-Ethernet L2: Profinet, Modbus, EtherNet/IP
- Example: Ethernet frames
Layer 3 - Network Layer:
- IPv4 and IPv6 are predominant.
- Non-IP L3 Protocols: MPLS, OSPF, BGP
- Example: IPv4 addressing and routing
Devices and Services in a Data Center:
- Devices: Routers, switches, load balancers, firewalls
- Services: DHCP, DNS, NAT
- Example: Cisco Catalyst switches
Layer 4 and Layer 7 (Application):
- Layer 4: Transport layer (e.g., TCP/UDP)
- Layer 7: Application layer (e.g., HTTP/HTTPS)
- Example: Load balancing using F5 BIG-IP (Layer 4-7)
Software-Defined Data Center (SDDC):
- Components: Cisco Unified Computing System (UCS), Cisco Nexus
- Functionality: Virtualization, automation, orchestration
- Example: Cisco UCS blade servers
Networking Protocols and Technologies:
- Switching and Routing Protocols: Spanning Tree Protocol (STP), OSPF, BGP
- Wireless: Wi-Fi standards (e.g., 802.11ac)
- Networking Security: Firewall, IDS/IPS
- Convergence in Switches: Unified Fabric (e.g., FCoE)
- Subnet, VLAN, VXLAN, VRF: Segmentation and isolation
- Fiber Types: LR (Long-Range), SR (Short-Range), MM (Multimode), SM (Single-Mode)
Classification of Networking Technologies:
- Subnetting and VLANs for network segmentation.
- VXLAN (Virtual Extensible LAN) for overlay networks.
- VRF (Virtual Routing and Forwarding) for logical isolation.
- Fiber types for data transmission over varying distances.
Storage hardware
- SAN: High-speed network for block-level storage.
- NAS: File-level data storage solution.
- Open Source Options: TrueNAS, OpenNAS offer customizable, cost-effective storage.
Storage Protocols
In the datacenter landscape, storage protocols play a pivotal role in determining how storage resources are accessed and managed across the network. Different protocols offer varying levels of performance, scalability, and reliability. This high-level comparative analysis aims to elucidate the key characteristics of popular datacenter storage protocols, namely Ceph, iSCSI, FoE, FCoE, FC, NFS, and SMB. Below you may find a quick comparative analysis of various datacenter storage protocols.
- Ceph
- Type: Object-based storage
- Protocol: RADOS (Reliable Autonomic Distributed Object Store)
- iSCSI (Internet Small Computer System Interface)
- Type: Block storage
- Protocol: SCSI over TCP/IP
- FoE (Fibre Channel over Ethernet)
- Type: Block storage
- Protocol: Fibre Channel encapsulated over Ethernet
- FCoE (Fibre Channel over Ethernet)
- Type: Block storage
- Protocol: Fibre Channel over Ethernet
- FC (Fibre Channel)
- Type: Block storage
- Protocol: Fibre Channel
- NFS (Network File System)
- Type: File-based storage
- Protocol: NFS
- SMB (Server Message Block)
- Type: File-based storage
- Protocol: SMB/CIFS
- Performance
- Ceph: High scalability but moderate latency
- iSCSI: Moderate performance, tunable for specific needs
- FoE: Comparable to FC, lower than FCoE
- FCoE: High performance, close to native FC
- FC: High performance and low latency
- NFS: Good for file-based operations, moderate performance
- SMB: Good for Windows environments, moderate to high performance
- Scalability
- Ceph: Highly scalable
- iSCSI: Scalable with hardware
- FoE: Limited by Ethernet bandwidth
- FCoE: Scalable but requires high-quality hardware
- FC: Limited scalability
- NFS: Scalable within the constraints of the file system
- SMB: Scalable, especially in newer versions
- Complexity and Management
- Ceph: Complex to set up but easy to manage
- iSCSI: Moderate complexity
- FoE: Simple setup
- FCoE: Complex due to FC and Ethernet requirements
- FC: Complex and specialized hardware
- NFS: Easy to set up and manage
- SMB: Easy in Windows environments
- Cost
- Ceph: Cost-effective due to open-source nature
- iSCSI: Moderate cost
- FoE: Lower cost than FC but higher than iSCSI
- FCoE: High cost due to specialized hardware
- FC: High cost
- NFS: Low to moderate cost
- SMB: Licensing costs in Windows environments
Disk Performance Levels
In the realm of datacenters, storage performance is a critical factor that directly impacts the overall system performance and user experience. Disk storage solutions vary in terms of speed, latency, throughput, and reliability. This discussion aims to provide an in-depth understanding of different types of datacenter disks and their performance metrics, followed by a comparative analysis. The following types of disks are available.
- HDDs
- IOPS: Low (80-180)
- Throughput: Moderate (~150 MB/s)
- Latency: High (5-8 ms)
- Endurance: High (in terms of years)
- SSDs
- IOPS: High (up to 100,000)
- Throughput: High (up to 550 MB/s)
- Latency: Low (< 1 ms)
- Endurance: Moderate (depends on the type of NAND)
- Hybrid Drives
- IOPS: Moderate
- Throughput: Moderate
- Latency: Moderate
- Endurance: High
- NVMe Drives
- IOPS: Very High (up to 1,000,000)
- Throughput: Very High (up to 5 GB/s)
- Latency: Extremely Low (< 100 µs)
- Endurance: High
Internet Connectivity and Interconnections
ISP Tiers and Connectivity
Data centers often connect to multiple ISPs across different tiers to ensure high availability, fault tolerance, and optimal routing.
- Tier-1 ISPs: These are the backbone providers that offer global coverage. They're interconnected in a 'peering' arrangement, meaning they allow traffic to flow between each other without charging. Connections to Tier-1 ISPs ensure that a data center has access to a fault-tolerant and extensive network infrastructure.
- Tier-2 ISPs: These are regional or national providers. While they have their own networks, they still need to purchase transit to reach certain parts of the Internet. They are important for localized services and can often provide more tailored solutions.
- Tier-3 ISPs: These ISPs are the last-mile providers connecting to the end-users. They purchase transit from Tier-2 or Tier-1 ISPs. Although less common, some data centers might connect to Tier-3 ISPs for specific edge computing requirements.
Border Gateway Protocol (BGP)
BGP is the routing protocol used to make core routing decisions on the Internet. It operates by establishing a session between two routers and exchanging routes, which are then stored in a Routing Information Base (RIB). BGP provides the flexibility to enforce policies that dictate which paths are chosen for sending data.
- BGP Peering: This is established directly between two ISPs to route traffic between them efficiently.
- BGP Transit: This involves a customer or downstream network purchasing the ability to forward packets through an ISP.
Autonomous System Numbers (ASN)
ASNs are unique identifiers for each network on the Internet. An ASN allows for a coherent routing policy as BGP advertises routes that are available within its autonomous system. ASN is a unique identifier that enables the grouping of IP prefixes and aids in the BGP routing process. Understanding these two elements is crucial for anyone involved in network engineering, cloud computing, and other IT disciplines. BGP uses ASNs to identify networks and make routing decisions. AS_PATH attribute in BGP includes the sequence of ASNs that a route has traversed.
Regional Internet Exchanges (IXPs)
Data centers often connect to regional IXPs to facilitate more efficient data exchange. For instance, GRIX (Greece Internet Exchange) is a neutral, not-for-profit IXP that interconnects various networks in Greece. IXPs are essential for reducing latency and bandwidth costs by allowing direct, cost-effective data exchange between member networks.
Datacenter Engineering Toolkit
Datacenter engineers are responsible for the maintenance, configuration, and reliable operation of computer systems and servers within a datacenter. To perform these tasks effectively, they require a set of specialized hardware and software tools. Below is a curated list of the most significant tools that a datacenter engineer must have for connecting to datacenter equipment and troubleshooting issues.
Hardware Tools
- Laptop with Virtualization Support
- Purpose: To run multiple operating systems for compatibility testing and direct system access.
- Business Justification: Enables engineers to emulate different environments for troubleshooting and system checks.
- Technical Specification: A high-performance laptop with a multi-core processor, ample RAM, and SSD for fast data access.
- Console Server
- Purpose: To provide remote access to multiple servers and networking devices.
- Business Justification: Facilitates remote troubleshooting, reducing the need for physical presence and thereby reducing downtime.
- Technical Specification: A console server with at least 16 ports for scalability.
- Serial-to-USB Converter
- Purpose: To connect legacy systems that require serial connections to modern laptops.
- Business Justification: Ensures backward compatibility and extends the life of older systems.
- Technical Specification: USB 3.0 to RS-232 DB9 Serial Adapter Cable.
- Ethernet Cables and Crimping Tools
- Purpose: For physical connectivity between devices.
- Business Justification: Enables quick setup and repair of network connections, reducing downtime.
- Technical Specification: Cat 6 or Cat 7 Ethernet cables and a high-quality crimping tool.
- Cable Tester
- Purpose: To test the integrity of network cables.
- Business Justification: Helps in early detection of faulty cables, preventing potential network failures.
- Technical Specification: A tester that supports both RJ45 and RJ11 cables.
- Power Supply Tester
- Purpose: To test the integrity of power supplies.
- Business Justification: Ensures that power supplies are functional, reducing the risk of unexpected shutdowns.
- Technical Specification: A tester compatible with ATX, BTX, and ITX power supplies.
- Portable Network Analyzer
- Purpose: To analyze network traffic and performance.
- Business Justification: Helps in diagnosing network issues and optimizing performance.
- Technical Specification: A device that can capture and analyze packets in real-time.
- Multimeter
- Purpose: To measure various electrical properties like voltage, current, and resistance.
- Business Justification: Essential for diagnosing electrical issues, thereby preventing potential damage.
- Technical Specification: A digital multimeter with auto-ranging capabilities.
- KVM Consoles. Keyboard, Video, and Mouse (KVM) consoles are crucial for managing multiple servers from a single interface.
- Console Cables. Various types of console cables, such as Ethernet-to-USB, USB-to-Ethernet, switch, and router console cables, are necessary for direct hardware interfaces.
- Screwdrivers and Tools. Electrical screwdrivers, torque wrenches, and nut drivers designed for the intricacies of server hardware.
- Safety Equipment. Electrically insulated gloves, safety goggles, and ESD wristbands to ensure safe operation in an electrically charged environment.
Software Tools
- SSH Clients
- Purpose: For secure remote access to servers.
- Business Justification: Enables secure and encrypted communications between the engineer's laptop and the server.
- Technical Specification: Software like PuTTY or OpenSSH or WinSCP.
- Virtual Network Computing (VNC), Spice, SFTP and RDP clients
- Purpose: For remote desktop access.
- Business Justification: Allows engineers to control servers and workstations remotely, reducing the need for physical presence.
- Technical Specification: Software like RealVNC or TightVNC.
- Packet Sniffing Software
- Purpose: To analyze network packets.
- Business Justification: Helps in diagnosing network-related issues and security monitoring.
- Technical Specification: Software like Wireshark or tcpdump.
- Troubleshooting tools and Live CDs. Having a live CD, such as Kali Linux, as well as the Windows SysInternals tool suite is of paramount importance. For Linux, strace and lsof along with the following common troubleshooting tools should be used.
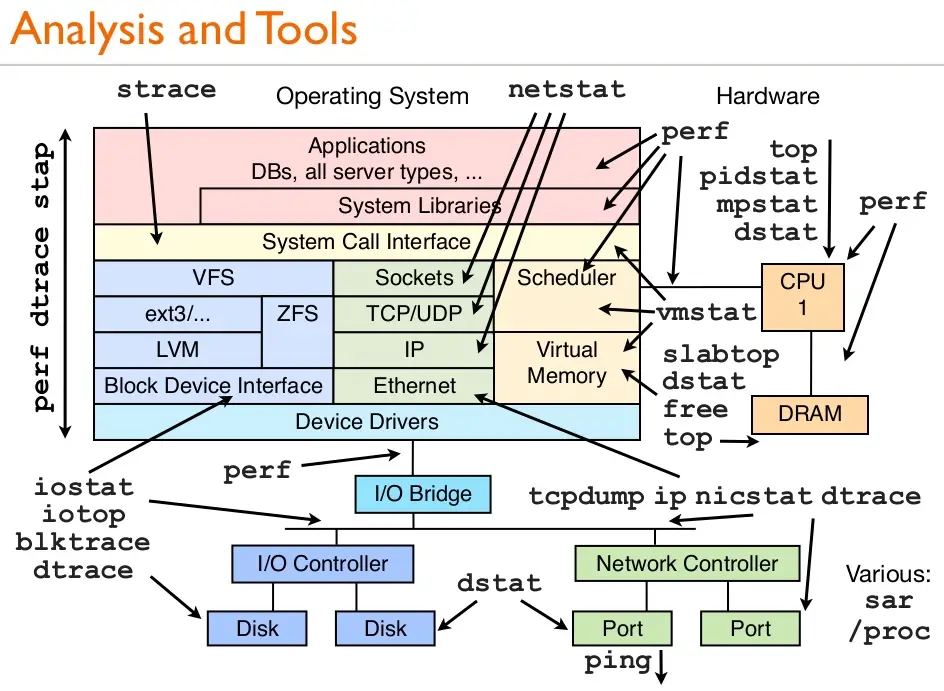
- Infrastructure Monitoring. Solutions like Grafana for real-time monitoring metrics, and Nagios for infrastructure health, are vital for proactive maintenance.
- Configuration Management. Ansible, Puppet, or Chef for automating the configuration of servers, ensuring uniform settings across the board.
Data center SLA, billing and cost management
In today's digital age, data centers play a pivotal role in supporting businesses and organizations, making it crucial to ensure their efficiency, reliability, and cost-effectiveness. In this technical blog post, we will delve into the critical aspects of Data Center Service Level Agreements (SLA), billing methodologies, and effective cost management strategies to help data center operators and IT professionals optimize their operations.
Understanding Data Center SLAs
Service Level Agreements (SLAs) are a fundamental aspect of data center operations. These agreements outline the performance expectations and responsibilities of both data center providers and customers. Key considerations include:
- Availability: SLAs define uptime commitments, often measured in "nines" (e.g., 99.9% uptime). A higher percentage signifies greater reliability.
- Response and Resolution Times: SLAs should specify response times for incidents and the expected time for issue resolution.
- Performance Metrics: SLAs may include performance indicators like latency, packet loss, and bandwidth.
- Penalties and Remedies: Define penalties for SLA violations and remedies for affected customers.
Billing Methodologies
Efficient billing practices are essential to ensure a fair and transparent financial relationship between data center providers and clients. Common billing methodologies include:
- Colocation Billing: Customers are charged for the space they occupy in the data center, power usage, and network connectivity.
- Metered Billing: Usage-based billing where customers pay for actual resource consumption, such as power, bandwidth, or storage.
- Fixed Billing: A flat fee structure, suitable for dedicated hosting or managed services.
- Blended Billing: Combining fixed and variable costs to offer a balance between predictability and flexibility.
- Tiered Pricing: Offering different service levels at varying price points, allowing clients to choose based on their needs.
Cost Management Strategies
Effective cost management is crucial for optimizing data center operations. Here are strategies to consider:
- Energy Efficiency: Implement energy-efficient technologies, such as hot/cold aisle containment, LED lighting, and advanced cooling systems, to reduce power consumption.
- Virtualization: Utilize virtualization to maximize resource utilization and reduce the number of physical servers required.
- Capacity Planning: Regularly analyze capacity needs and allocate resources efficiently to avoid over-provisioning.
- Asset Lifecycle Management: Maintain an inventory of data center assets and plan for their replacement or upgrades to prevent unexpected costs.
- Monitoring and Optimization Tools: Invest in monitoring tools to track resource utilization and optimize configurations for performance and cost.
- Cloud Integration: Explore hybrid cloud solutions to dynamically scale resources and reduce the need for fixed infrastructure.
Data center SLAs, billing, and cost management are intricate aspects of maintaining efficient, reliable, and cost-effective data center operations. By defining clear SLAs, selecting appropriate billing models, and implementing smart cost management strategies, data center operators and IT professionals can achieve the delicate balance of service quality and cost optimization, ensuring the continued success of their data center infrastructure.
Data center business continuity and disaster recovery (BCDR) planning
Data centers are the beating heart of modern enterprises, housing critical applications, and data. To safeguard these assets against potential disruptions, a robust Business Continuity and Disaster Recovery (BCDR) plan is essential. In this technical blog post, we will provide a comprehensive guide to BCDR planning for data centers, ensuring their resilience and uninterrupted operations, even in the face of adversity.
1. Risk Assessment and Impact Analysis
- Begin by identifying potential risks and threats that could disrupt data center operations, such as natural disasters, power outages, hardware failures, and cyberattacks.
- Perform an impact analysis to understand the consequences of these disruptions in terms of data loss, downtime, and financial impact.
2. Define Recovery Objectives
- Determine Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) for each application and system. RTO specifies the maximum acceptable downtime, while RPO defines the maximum acceptable data loss.
3. Data Backup and Replication
- Implement regular and automated backups for all critical data.
- Employ data replication mechanisms to maintain real-time or near-real-time copies of data in geographically diverse locations.
4. Redundant Infrastructure
- Ensure redundant power supplies, cooling systems, and network connections to mitigate single points of failure.
- Implement failover systems for critical applications and services.
5. Disaster Recovery Sites
- Establish secondary data center locations or cloud-based disaster recovery solutions to ensure data redundancy and application availability.
6. Virtualization and Containerization
- Utilize virtualization and containerization technologies to enable swift migration of workloads in case of hardware failures or maintenance.
7. Network Resilience
- Implement diverse network paths and BGP routing to maintain network connectivity during outages.
8. Security Measures
- Employ robust cybersecurity measures to protect against cyber threats and ensure data integrity during recovery.
9. BCDR Testing and Training
- Regularly test BCDR plans to validate their effectiveness.
- Train data center staff on their roles and responsibilities during a disaster.
10. Documentation and Communication
- Maintain detailed BCDR documentation, including recovery procedures, contact information, and equipment inventory.
- Establish clear communication channels and contact lists for stakeholders.
11. Continuous Monitoring and Improvement
- Implement monitoring tools to assess data center health and detect anomalies.
- Periodically review and update the BCDR plan to address evolving risks and technological advancements.
A well-structured BCDR plan is a lifeline for data center operations, ensuring business continuity and resilience in the face of disasters. By performing risk assessments, defining objectives, implementing redundancy, and regularly testing and refining the plan, data center professionals can safeguard critical assets and maintain uninterrupted operations, even in the most challenging circumstances.
References
- "Datacenter as a Service: A Paradigm for the Age of Cloud Computing," IEEE Paper.
- "Inside the Microsoft Azure Cloud," Azure Official Documentation.
- "IT Essentials: PC Hardware and Software Companion Guide," Cisco Press.
- "Sysadmin's Essential Toolkit," Journal of System Administration.
- Uptime Institute - "Datacenter Tier Classification and Operational Sustainability."
- NFPA 75: "Standard for the Fire Protection of Information Technology Equipment."
- Data Center Map: Website
- Internet Engineering Task Force (IETF) on BGP: RFC 4271
- American Registry for Internet Numbers (ARIN) on ASNs: Link
- European Internet Exchange Association (Euro-IX) on IXPs: Link
- ANSI/EIA-310-D standard for 19-inch racks.
- "Data Center Handbook," by Hwaiyu Geng.
- "Data Center Fundamentals," Cisco Press.
- "Backup Power Solutions for Data Centers," Journal of Electrical Engineering.
- "Emerging Trends in Datacenter Cooling," IEEE Journal on Cooling Technologies.
- ISO/IEC 27001: "Information Security Management."
- https://stefanos.cloud/difference-between-ats-sts-standby-online-and-line-interactive-ups/
- https://stefanos.cloud/inside-azure-datacenter-architecture-with-mark-russinovich/
- https://cloudrock.gr
- https://azure.microsoft.com/en-us/global-infrastructure/
- https://download.microsoft.com/download/8/2/9/8297f7c7-ae81-4e99-b1db-d65a01f7a8ef/microsoft_cloud_infrastructure_datacenter_and_network_fact_sheet.pdf
- Risk Assessment Guide for Microsoft Cloud: https://docs.microsoft.com/en-us/compliance/assurance/assurance-risk-assessment-guide
- https://www.colocationamerica.com/blog/data-center-solar-power
- https://azure.microsoft.com/en-in/global-infrastructure/
- https://azure.microsoft.com/en-us/pricing/tco/calculator
- https://www.colocationamerica.com/data-center/tier-standards-overview.htm
- https://www.hpe.com/emea_europe/en/what-is/data-center-tiers.html
- Cisco UCS
- Cisco Nexus
- VXLAN Overview
- NIST Special Publication 800-34: Contingency Planning Guide for Federal Information Systems
- Business Continuity Institute (BCI) Good Practice Guidelines
- Service Level Agreement (SLA) Definition
- Data Center Cost Management Best Practices