A "good fit" or "best fit" or "sweet spot" is when a machine learning (ML) model can predict values for a system with the minimum error, ideally that error being zero. In this case, the ML model is said to have a good fit on the data. The good fit sits between the underfitting and overfitting areas and describes the capability of an ML model to generalize well to any new input data that is has not seen before in a certain knowledge/problem domain. The good fit is relevant to the ML model's accuracy and performance.
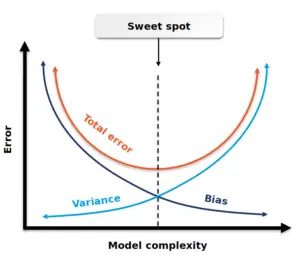
Initially the model may be oversimplistic and may have not have been adequately trained with training data. This is where the model lies in the underfitting area. An ML model then keeps on learning as it is being trained with data and therefore the error will keep decreasing. Because of noise and the less useful features in the data set, the model may become overfitted and its performance will decrease, after learning for a longer time than needed, i.e. after passing the point of good fit, which stands between the underfitting and the overfitting areas. If the model is underfitting or overfitting, what we observe is substantial difference between its performance and the corresponding model error values, between the training data and testing data. If the model reaches the good fit (best fit), then performance is equally good on the training and the testing data.
Two concepts which are closely related to the ML model good fit are bias and variance.
An intuitive and visualized explanation of what constitutes underfitting, overfitting and the best fit is provided in the following blog post: https://www.analyticsvidhya.com/blog/2020/02/underfitting-overfitting-best-fitting-machine-learning/.