In machine learning, normalization is a statistical technique by which the data in a dataset are transformed to have values in a normal (Gaussian) distribution, in the value range of [0,1] or in the value range of [-1. 1].
For each value x in the dataset, its corresponding normalized value x' is calculated in the value range [0,1] as follows.
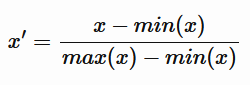
Alternatively, there can be a mean normalization (normalization variant), with normalized x' values in the [-1,1] range, which is calculated as follows.
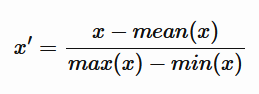
It is important to differentiate between normalization, standardization and regularization. Normalization and standardization are data preparation (feature engineering) methods, while regularization is used to improve the performance ML models, by adjusting the cost function to eliminate the ML model error by using the regularization hyperparameter. Standardization and normalization are very similar techniques, in that they both change the scale of data to better accommodate for an ML algorithm operations.
It must be noted that normalization must be used when the x variable data does not follow a normal (Gaussian) distribution or when the data distribution is unknown.